2012年01月28日
キャラの性別はどんな根拠があれば確定するのか
TVアニメの『ギルティクラウン』を毎週楽しく見ている。
このアニメのいいところはなんといっても、「これは本来なら百合であるべきだ」と憤らずに済むところだ。
最近では少なくなったが昔は、「誰がどう考えてもこれは百合展開になるに決まってんだろうが! それがなんでこんな超展開になるんだよこの糞ヘテロセクシスト!」と怒鳴りつけながら監督の首を絞め上げてやりたいような、ひどい作品が多かった(たとえばこれはアニメではなく原作の問題だが、『ラブひな』の瀬田先輩は誰がどう考えても女であるべきだった)。今でもその危険を感じると身構えてしまう。そういう気苦労なしに見られるのは嬉しい。
また百合に限らず、「これは本来なら××であるべきだ」と憤ることがほとんどない。今週のいのりの殺しっぷりや、嘘界の「処世術だ」には痺れた。そう、フィクションはこうでなくては。
「これは本来なら百合であるべきだ」というのは、さきほどの例がそうだったように、「このキャラは女であるべきだ」というパターンが多い。逆に腐女子諸氏にとっては「このキャラは男であるべきだ」なのだろうと思う。この観点から『ギルティクラウン』を見ると、いのりは男であるべきだったようにも見える。
さて本題。
いのりは男であるべきだったようにも見える、と思った瞬間、私は気づいた――いのりの性別はまだ確定していない。女装かもしれない。
普段から女装キャラを警戒するあまりの思い過ごしだろうか。しかし、女装キャラが「男の娘」などともてはやされる昨今なら、1クールやそころ引っ張ってから女装とバラすくらいのことはありそうではないか。
こうして疑い始めてみると、そもそも、キャラの性別はどこまでいけば確定するのか。いったいどんな根拠があれば、女装ではないと考えていいのか。
とりあえず、ギャグやSFでない世界では、
・妊娠出産
SFなら、
・宇宙人
・ロボット
これらは性別があってないようなものだから、女装も意味がないのでやらない、と考えていい。
上の3つほど確度は高くないが、
・真正面からのフルヌード
・セックス
・脇役との連れション的なつきあい
さらに確度の下がるものとして、
・幼少のころのエピソードでもちゃんと女
・ナイーブな「男って」「男だからって」発言
・「男勝り」的な勝気さの発露
くらいが思いつく。
そして私が思いつくかぎり、かなり確度の低いものを含めても、いのりが女装でないとする根拠はまだ出ていない。逆に「お色気」や「芸能」や「友達づきあいがない」や「家族が未登場」などの危険要素はたっぷり持っている。
もしこれが百合なら、ヘルメットとプロテクターを着用して身構えるところだが、幸い百合ではないので楽しく見られる。
2012年01月27日
ステマ工作員募集
西在家香織派は紅茶ボタンをステルスマーケティングしてくださる工作員を募集します。
iPhoneアプリの電子書籍はサクラレビューによるステルスマーケティングだらけ
応募はApp Store / Android Marketの紅茶ボタンのレビュー欄にて受け付けます。素敵なサクラレビューで募集担当者のハートを見事キャッチしてくださったかたを最大0名採用します。お気軽にご応募ください。
2012年01月25日
Array Considered Harmful あるいは、なぜC言語のポインタは難しいのか
大昔、子供向けのBASIC入門の本を読んだら、「配列でつまづく人が多い」と書いてあったのを覚えている。
今でも配列――今ではたいてい「リスト」という格好いい名前がついている――を使うときには、「これこそプログラミングの味!」とでも言うべき不自然さを感じて、抵抗を覚える。
たとえばループ変数の名前、i。なぜいつも同じ名前、つまり意味のない名前なのか。よい名前がつけられないということは、なにかがうまくいっていないということだ。
この点で、関数オブジェクトとmapは文句なく正しい。が、それで配列まで正しくなるのか。
配列とは値の集合であり、少なくとも以下の3つの性質がある。
1. 重複を許す(多重集合)
2. 要素間には前後の順序がある(全順序)
3. 配列の各要素は連続した整数と1対1対応する(インデックス)
「プログラムでなにをしたいか」という観点から考えた場合、多重集合の性質しか使わない場合が多い。全順序は使うこともあるが、インデックスまで使うことは皆無に近い。使われない性質は余計なものであり、人を混乱させる以外なにもしていない。
たとえば、財布に硬貨が総額いくら入っているか調べることを考えてみよう。
硬貨を一枚ずつ取り出して額面を加算してゆく、というアルゴリズムを考えられないような大学生はおそらくいない。このとき財布は硬貨の多重集合であり、硬貨同士のあいだに順序はない。
が、もし配列しかデータ構造がなければ、どうなるか。全順序でインデックスつきの奇妙な財布が出現してしまう。
さらに、mapのない言語では、インデックスをプログラム上で使うことになる。アルゴリズム上では、硬貨を取り出す順序は偶発的なものであり、財布に備わっているものではない。ところが、もし配列しかデータ構造がなければ、硬貨を取り出す順序ばかりか、それが何番目かという数字までデータ構造に焼き込むことになる。おかしな話だ。
硬貨のかわりに紙幣ではどうか。
財布のなかの紙幣はたいてい重ねてあるので、順序がある。これならデータ構造が順序を持っていても別におかしな話ではない。重ねてある順序で紙幣を取り出すのも、必要なことではないが自然だ。しかし今度もインデックスはいらない。たとえば配列ではなくスタックでも表現できるし、そのほうが自然だ。
データ構造にインデックスが必要になるのは、配列の要素が他のところから参照される場合だけだ。
要素のIDとして考えると、インデックスの多くの性質は不要になる。連続した整数である必要はないし、そもそも整数である必要もない。だから実際、IDとしての役割はポインタや「参照」に取って代わられ、インデックスで参照するデータ構造など今ではバイナリファイルでしかお目にかかれない。
配列とはおかしなものであり、高級言語の扱うべきデータ構造としては箸にも棒にもかからない欠陥品である。
この欠陥品を、少し便利で死ぬほど厄介にしたのがC言語のポインタである。こんなものがわかるのは、配列脳の持ち主だけだろう。
2012年01月23日
インタプリタがコンパイラになる話
4半世紀前に「BASICコンパイラ」に憧れた皆様こんにちは。
当時、インタプリタとコンパイラは格が違う存在だった。
・ホビイストはインタプリタ、プロはコンパイラ
・無料でパソコンについてくるのがインタプリタ、何万円も出して買うのがコンパイラ
・起動してすぐに使えるのがインタプリタ、段取りが多くて敷居が高いのがコンパイラ
そしてなにより、
・遅いのがインタプリタ、速いのがコンパイラ
パソコン雑誌の広告等で「コンパイラ」を見て憧れを募らせていた私は、Javaや.NETのJITコンパイラに騙されているような気が今でも少しする。インタプリタなのかコンパイラなのかどっちなんだ、と詰め寄りたくなる。
もちろん、(昔の)インタプリタと(昔の)コンパイラのどちらと比較しても優れているのがJITコンパイラだということは知っている。それでも、あの絶対的な格の違い、越えられない壁はいったいどうなってしまったんだ、という気持ちにかられる。
そして今度は、インタプリタがJITコンパイラになるという。
PyPy を使ってインタプリタを書く
これを見て私の脳内には、BASICインタプリタに魔法をかけるとBASICコンパイラに変身する、という夢のような光景が展開された。ちなみにPythonではベンチマークが3倍速になるという。
(といっても既存のコードがそのまま3倍速になるわけではない。多くのソフトウェアはI/Oのために内部表現と外部表現を変換するところがボトルネックになっており(JavaのJNIが遅いのはこれ。「速度が必要なところはCで書けば~」という議論が成り立たない最大の理由)、PyPyはその変換に余計な手間がかかるので、I/Oの多いソフトウェアではかえって遅くなる)
格や夢のことはさておき現実問題としては、メリットは速度だけなので、実のところほとんどどうでもいい。が、「書きやすさ」や「開発のしやすさ」と違って速度は定量的に比較できるので、比較してみたくなる。こう書くとまるで経済学者と街灯の話だが、まさにそのものだ。
「Pythonでは3倍速」といっても、比較対象は別に速度自慢でもないPythonにすぎない。相手がJava VMではどうか。では試してみるか、と思って、上にリンクした紹介を真に受けた私はJava VMのサブセット(マイクロベンチマークが取れる程度のもの)を書こうとして、クラスファイルのパーサを書いたところで心が折れた。
PyPyでインタプリタを書くのに使う言語はRPythonといい、Pythonのサブセットということになっている。……と書くと、書きやすい言語のように聞こえるかもしれない。上の紹介でも「これらはそれほど難しくはありませんよね?」などと愛想のいいことが書いてある。
真っ赤な嘘だ。
RPythonは、
・型に厳密
ひとつのリストや辞書には同じ型のオブジェクトしか入れられない。しかし型を宣言しないPythonでどうやって型に厳密にするのかというと、
・型を推論し、暗黙の型宣言をつける
C#のvarのような型推論なら便利なものだが、暗黙の型宣言となるとあまり穏やかでない。とはいえ、これだけならまだ大した問題ではないが、
・ジェネリックプログラミングができない
なにしろPythonは型の緩い言語なので、テンプレートも総称型もない。すべてのメソッドには唯一の暗黙の厳密な型宣言をつけられるように書かなければならず、そのため同じ中身のメソッドを引数の型ごとに書かなければならない。重要な組み込み関数でも、唯一の暗黙の型宣言がつけられないものは削られている。たとえばmap()は削られている。
ここまでならまだ乗り越えられない壁でもない。が、この上さらに、
・Hello, worldのコンパイルに60秒かかる
「コンパイルしない方法もあってそれだともっと早くできる」という情報もあるが、型チェックが手薄なのかどうかで役に立たなかった。
疑問――なぜPyPyの作者はRPythonなどという世にも使いにくい言語を作る必要があったのか?
魔法の都合上、型に厳密な言語が必要なのはわかる。が、それならML系の言語ではなぜいけなかったのか。まるで見当がつかない。
もし、最初から型に厳密な言語として設計された既存の言語でインタプリタを書けるようになったら、JITコンパイラの恩恵も世に広まるだろう。それまでは無理だ。
一応そのパーサを載せておく。RPythonの恐怖をまだ知らない向きは、私の遺志を継いで、Java VM(のベンチマーク用サブセット)に挑戦されたい。
2012年01月19日
Coders at Work まとめ おまけ
『Coders at Work』まとめ Part 3の続き。
おまけと言いつつ、今度こそ本当にまとめる。と言いつつ感想を書く。
・C++は明らかにダメ
・デザインパターンには問題がある
・メモリ共有型のマルチスレッドは明らかにダメ
・トランザクショナルメモリは今ホットだが疑問。ちなみにMicrosoft Researchの研究者はダメと結論づけた
・何層ものレイヤを重ねることには不安がある。その上さらにレイヤがブラックボックスなのは明らかにダメ
・プログラミング言語が格納域を扱うことには問題がある
・Prologはもっと注目されるべき
・純粋関数型言語は注目はされているが、うまくいってはいない
・ソフトウェアの再利用はうまくいっていない
・コンピュータにはこの数十年間、見るべき進歩がない
私見:
先日、fingertreeというデータ構造を知った。私の感想――「これは早すぎる最適化だ」。
Fran Allenいわく、「ある計算には良いことが別の計算にはよくないということも出てくるでしょう。ある整理方法が、マトリックスのようなシンプルなものでさえ、違ったやり方でアクセスした場合にはまずいものになり得ます。だからアクセスの順序と場所の組み合わせによるのです」。
どんなデータ構造が最適かは、実行してみるまでわからない。もちろん理論上は、実行前に予測することも不可能ではない。が、そういう予測はほぼ常に、惨憺たる結果に終わる。たとえコードを書いた瞬間には予測が当たっていても、そのうち外れる。プログラムは変化してゆくものであり、「アクセスの順序と場所の組み合わせ」も変化してゆくからだ。
何種類かのデータ構造をあらかじめ用意しておき、実行時にVMがプロファイリングにもとづいて最適なデータ構造を選択する? それが未来だとは思えないし、現状から移行するほどの価値があるとも思えない。
ではどうすればいいのか。
最適なデータ構造を選択するプログラムではなく、作り出すプログラムを作り出すべきだ。
それも、たとえばJavaのjava.util.Mapがインターフェイスでjava.util.HashMapが実装、といったレベルの抽象化では足りない。そもそもmutableなデータ構造は格納域を扱っている。immutableなら格納域の問題はないが、それが実際に機能しうる解決策なのかどうかわからない。少なくとも私は、「クリス・オカサキの本、"Purely Functional Data Structures"」を見て首をかしげた。
もしかすると、「データ構造」という概念そのものに問題があるのではないか。配列――たぶん最初のデータ構造――が現れたときから、私たちはずっと道を誤っているのではないか。
おそらく、まだ誰の夢想にも現れていないアイディア、「一夜にして様相を変えるようなもの」が必要とされている。私の生きているうちにそのアイディアが現れるかどうかわからないが、それは必ずある、と私の勘が告げている。
Coders at Work まとめ Part 3
『Coders at Work』まとめ Part 2の続き。
第11章 L Peter Deutsch
・(巨大なソフトウェアについて)
アボガドロ数はご存じでしょう。10の23乗でしたか。だから世界にはものすごい数の小さなものが詰まっていて、同時にたくさんのことが起きています。私たちがそれで患わされることがないのは、たとえばこのテーブルを素粒子レベルで理解する必要がないからです。
みんなソフトウェアでモジュール化構造を作ろうと試みており、時と共に技術水準は進歩していますが、それでも、私の意見では、周りを見回して10の23乗個の原子をもったものを目にしながら気後れさせられることのないものの世界の簡単さには、遠く及びません。
ソフトウェアというのは詳細の学問で、それはソフトウェアにまつわる深くぞっとする根本的な問題です。すべての細かい部分同士がどうやり取りするのかいちいち考えずに済むようにできる、ソフトウェアを概念化し組織化する方法が分かるようになるまでは、物事はあまり良くはならないのです。そして私たちはそこから遠く離れたところにいます。
・(それは変えることができる?)
始めからやり直す必要があるでしょう。ポインタの概念を持った言語をすべて捨てることです。現実の世界にはポインタのようなものはないのですから。情報というのは場所を取るものであり、時を経て存在し、特定の位置を占めるという事実を、把握できるようになる必要があります。
・私が「記号の世界」と呼んでいる場所は、私にはいつも非常に快適でした。記号とそのパターンというのは、私がいつもランチに食べているものでした。多くの人はそうではありません。私のパートナーでさえそうです。私たちはどちらも音楽家であり、どちらも作曲家であり、どちらも声楽家です。しかし私は音楽の世界に記号という視点でやってきたのです。私は作曲の多くを鉛筆と紙だけでやります。音符はそこにありますが、ピアノから拾い出すわけではありません。彼はそれを聞き、構想を得るのです。
一方で彼は作曲の多くをギターでやります。彼はギターを弾き、いじり回し、あるいはピアノを少し鳴らし、再び弾き直します。
#「パートナー」が「彼」であることに注目。これ自体は驚くに値しないが、あとで驚愕することになる。
・問題は、ビジネスの世界で古くからある言い回しですが、「早い、安い、良い。……どれでも2つ選んでください」というものです。早く構築するなら、安く作る方法はあったとしても、なおかつ良いものにはなりそうにありません。
・プログラミング言語については、この40年で質的には進歩していないと強く主張できます。今日使われているプログラミング言語で、Simula-67より質的に優れていると言えるものはありません。奇妙に聞こえるだろうことは分かっていますが、本当にそう思っています。JavaはSimula-67よりさして良くなっているとはいえません。
・(Smalltalkも?)
SmalltalkはSimula-67よりいいとは思いますが、今日のSmalltalkは1976年にはすでにあったのです。今の言語が30年前にあった言語より良くないと言っているわけではありません。私が現在あらゆるプログラミングに使っているPythonは、30年前にあった何よりもずっと良いと思います。Smalltalkよりも好きです。
私は「質的に」という言葉をとても注意して使っています。今日広く使われているプログラミング言語はすべて、ポインタの概念を持っています。それよりも質的に優れた基本概念に基づくソフトウェア構築方法というものを私は知りません。
・(PythonやJavaの参照もポインタ?)
そうです。PythonやJavaで作られたプログラムであっても、ある小さなスケールを過ぎると、すべて同じ問題にぶつかります。CやC++におけるメモリ破損の問題はなかったとしても。
問題の本質は、システムの情報共有や情報アクセスのパターンを理解し、記述し、制御し、推測する言語的なメカニズムがないということです。ポインタを渡すとか格納するというのはローカルな操作ですが、その帰結は暗黙にグラフを作るということです。マルチスレッドアプリケションの場合については触れないでおきましょう。シングルスレッドアプリケーションにおいてすら、プログラムの別な部分の間を流れるデータがあります。プログラムの違った部分に伝搬するリファレンスがあります。そして最高に良く設計されたプログラムでも、進行する2つとか3つとか4つの異なる複雑なパターンがあり、細かい部分で起きることを実際に制約するように、大きなユニットの性質を記述し推測し特徴づける方法はないのです。みんなこの問題でやられています。しかしこれに関してブレークスルーがあったとも、広く受け入れられ、広く使われている解決法があるとも見えません。
・(関数型言語は?)
ええ、純粋関数型言語は異なる種類の問題を抱えているにしても、確かにこの難問にある答えを出していますね。
・私が言語設計の目論見に実際踏み出さなかった最大の理由はたぶん、共有のパターンやコミュニケーションのパターンを、十分高いレベルで、十分結合可能な仕方で記述する方法を見いだせるだけの洞察を、やってのけられるほど持ち合わせていると自分で思えないからです。しかしこれは今日のソフトウェア構築が30年前からわずかにしか良くなっていない理由だとも思います。
・(さまざまな種類のアサーションについて)意図したとおりに動くソフトウェアへの道は、アサーションではなく、帰納的アサーションでもなく、より良く、より強力で、より深い宣言的記法にあると思っています。
私が好きなコンピュータにまつわる警句の作者のジム・モリスは、型チェッカーはネアンデルタール人の証明器だと言っています。もしブレークスルーが起こるとしたら、それはプログラムがどう構成され何をすると意図されているのかを宣言的に記述する、もっと強力な方法から来ると思います。
・もはやLispでプログラムを書かなくなったのは、あのシンタックスに我慢できなくなったからです。シンタックスが重要だというのは紛れもない人生の真実です。
・言語システムというのは3本脚の上に立っています。言語があり、ライブラリがあり、ツールがあります。言語の成功は、この3つの複雑な絡み合いに依存しているのです。Pythonには素晴らしい言語があり、素晴らしいライブラリがあり、そしてツールはほとんどありません。
・(Lispのシンタックスに我慢できなくなった理由について)平方インチ当たりの情報の密度は、中置記法の言語の方がLispよりも高いのです。
・(中置記法の利点について)中置記法の世界では、すべてのオペレータは2つのオペランドと隣り合っています。前置記法の世界ではそうなっていません。もう1つのオペランドを見るために余分な手間がかかるのです。そんなことはみんな小さなことだと思うでしょうけれど、私にとって最重要なのは平方インチ当たりの情報密度なのです。
#思えばオブジェクト指向言語の文法は、関数名の中置記法。
・私はコーラスで何年も歌っていましたが、2003年の夏に、私たちはツアーでイタリアの古い教会で6回コンサートをしました。その旅行には妻も同行し、ヨーロッパにさらに2、3週間滞在することにしました。
#「パートナー」は「彼」なのに、一緒に旅行するような「妻」がいる!?!?!?
・(ソフトウェア開発の仕事から手を引いたことについて)
そして突然気づきました。私がワクワクするようなソフトウェアプロジェクトを見つけるのに苦労していたのは、プロジェクトを見つけるのが問題なのではなく、ソフトウェア自体にもはやワクワクしないからなのだと。今から思うとバカみたいに見えますが、私がソフトウェアに打ち込んでいたそもそもの理由は、それによって世界をより良い場所へと変えられると思っていたからなのでした。もうそんなことを信じてはいません。少なくとも前と同じようには。
第12章 Ken Thompson
・(もっと違ったようにプログラミングを学びたかった?)
ええ、もちろん。高校のときにタイピングを習っておけばと思います。今でもタイピングが下手で困っています。でも何もしようと思わなかったし、何もしませんでした。そういうけじめがないんです。私はいつでも次にやりたいことをやって終わりです。私にもっと先見性とか計画性みたいなものがあれば、タイピングのようなことはチャンスのあるときにやっていたと思います。あとは数学をもっと深く学んでいたらとは思いますね。数学が役に立つような場面に確かに出くわしますから。そういった小さなことはたくさんあります。しかし昔に戻ってもう一度やり直さなければならないとしても、何も違ったようにはやらないだろうと思います。基本的に私は何も計画せず、ただ次のステップへと進むだけです。そしてもう一度やらなければならなかったとしても、同じようにただ次のステップを取っていくだけです。
・私はコードにはこだわりません。半分進んだところで別なやり方を見つけたなら、ただハックして乗り越えます。私の知っている人の多くは、一行のコードをいったん書いてしまうと、バグでも出ない限りは、それがそのままずっと固まってしまいます。とくにAPIのあるルーチンを書いていて、APIをどこか、封筒裏なりAPIリストなりに書いていようものなら、それで終わりです。どんなにまずかろうと二度と変えられることはありません。私の場合は、もっと良いやり方や分割の仕方を見つけたときには、喜んでまたばらします。既存のコードに執着することはありません。コード自体は常に劣化していくもので、書き換えるにしくことはありません。何も変わらなかったとしても、何かの理由で劣化するのです。
#「コード自体は常に劣化していく」とは仙人か天使でなければ公言できない真実。
・(コードを捨てるのはいつ?)扱うのが難しくなったときです。私はほとんどの人より早く見切りをつけます。何かを付け加えたいと思い、それを付け加えるのが難しすぎると感じたらすぐにコードを捨てます。捨ててはじめからやり直し、自分のやりたいことが容易にできる別な区分けを考え出します。私が何かを捨てる引き金はとても軽いのです。
#またもや仙人天使発言。
・(Cのポインタはメモリ破壊を引き起こす機能であり、GCする言語のほうが安全、という議論について)
バグはバグです。バグがある原因は、自分でそれを作ったからです。実行時の安全性という意味で安全な言語なら、悪用し得るバッファオーバーフローを起こすかわりにオペレーティングシステムがクラッシュするだけです。「死のping」はオペレーティングシステムのIPスタックでした。死のpingはもっとあったのではないかと思います。「スーパーユーザになってマシンを乗っ取るping」はなくなったとしても「死のping」は残るでしょう。
#「100パーセント安全でなければダメ」論。彼は天国に住んでいるらしい。Plan 9?
・(1999年のインタビューで、もうコンピュータは研究されつくしているので、コンピュータではなく生物学に進むよう息子さんに言っているが、それから10年たって、どう思うか?)
考えは同じです。コンピュータの世界では予測できないような革新的なことは何も起きていません。一番最近の重要なものはインターネットだと思いますが、それは1999年にもありました。すべてが発展し、個々のコンピュータのスピードは格段に速くなっていますが、でも何が違うでしょう?
・(ハードウェアを極度に抽象化したプログラミングも楽しいのでは?)
やみつきにさせるものがありますが、自分の子どもに入り込むように言おうとは思わないでしょう。変わったのだと思います。私が年取っただけかもしれませんが、ほかのレイヤの上にある、ほかのレイヤの上に、さらに別なレイヤを作るだけというのでは、たとえば決定性有限オートマトンを作るときの利点は得られないように思います。必要に応じて新しいアルゴリズムは時と共にどんどん複雑になっていきます。1つの新しいアルゴリズムが、他の50個の小さなアルゴリズムに依存しているというような。私が若かったころは、そういった小さなアルゴリズムに取り組んでいて、それは楽しいものでした。それ自体で理解できるものでした。細かく場合分けし、それぞれの場合は聞いたことはあるけれどよく知らないアルゴリズムによって解かれるというような、会計みたいな仕事をする必要はありませんでした。だから変わったのです。変わっていると本当に思っており、その多くは、時と共にすべて階層化され、階層を扱うようになったことによるのだと思います。私は階層を理解するには頑固すぎるのかもしれません。
#しびれるねぇ(ピングドラム)。
第13章 Fran Allen
・(最後にプログラミングしたのはいつ?)
かなり昔のことです。Cが現れたころにやめてしまいました。あれは大きな一撃でした。私たちは最適化や変換について非常に進んでいました。大きな問題を1つひとつ解決していました。Cが現れたとき、SIGPLANのコンパイラの会議の1つで、Cを支持するベル研のスィーブ・ジョンソンと、当時私のやっていた自動最適化のプロジェクトにいたビル・ハリソンが議論をしました。
スティーブはプログラマが自分でやるからもはやオプティマイザを作る必要はないと主張しました。最適化はプログラマの問題なのだと。Cの設計の動機になったのは、高級言語では解決できなかった3つの問題です。1つは割り込みを扱うことです。もう1つはリソースのスケジューリングで、マシンのかわりにキューにあるプロセスのスケジューリングをするということです。3つ目はメモリ割り当てです。高級言語からはできませんでした。それがCの言い分でした。
#どれも現在では当てはまらない。私見では、Javaレベルの高級言語による素朴な超循環評価器が、Cで実装されキンキンに最適化されたVMよりも速くなる日は10年以内にやってくる。ハードウェアのアーキテクチャが複雑になるにつれて、手作業でのアドホックな最適化はますます不利になる。そしてCPUクロックの向上が止まった現在、ハードウェアのアーキテクチャは複雑さを増す方向に向かっている。GPUやマルチコアなど。
・1960年までには、見事な言語のリストができていました。Lisp、APL、Fortran、COBOL、Algol 60。Cよりも高級な言語です。Cが開発されて、私たちは大きく後退したのです。Cは自動最適化、自動並列化、高級言語からマシンへの自動的なマッピングといった私たちの能力を壊してしまいました。これはコンパイラが大学でもはや基本的に教えられなくなった理由の1つです。
・Cのような言語は問題の解決法を細かく決めすぎてしまうからです。そういう言語が、学問としてのコンピュータサイエンスを壊してしまったのです。
(中略)
根本にある問題はデータの場所を指定するということです。ほかの言語を見てもらえば、データの場所や、それをどう動かすか、マシンのどこに置くかということまで指定しようとはしないのが分かるでしょう。どの時点でも、究極的には値が問題にされていたのです。
・私たちが最適化の世界で計算についてやってきたことが、データについても行えるチャンスがあると思っています。私たちはデータをあまりうまく管理していません。データを自動的に管理する方法、一緒に使われるデータにローカル性を確立するための良い方法を私たちは持っていないのです。
とてもエキサイティングな研究の流れがたくさんあります。しかし欠けているのは、もっと大きく大胆なコンセプトです。多くのことは既存の枠組みや現在の考え方の範囲内で起きています。一夜にして様相を変えるようなものではありません。何百万行というコードがあります。しかし私たちは「これはここでやる、あれはあそこでやる」という境界を壊そうと試み始める必要があります。
・現在我々は基本的にリファレンスを使ってやっています。ハードウェアによって、あるいは下にあるオペレーティングシステムやサポートシステムによって動かされています。そしてリファレンスは多くの場合要素のレベルです。
・(つまり、構造体や配列の中を指すポインタを持てるというような意味で?)
ええ、要素の中にです。そしてそれが、ハードウェアやアーキテクチャのプロトコルに応じて、値をその使われる計算の部分へと運ぶのです。
しかし別な方法として、データの相対的な位置を最適化の対象として場所を整理することもできるでしょう。ある計算には良いことが別の計算にはよくないということも出てくるでしょう。ある整理方法が、マトリックスのようなシンプルなものでさえ、違ったやり方でアクセスした場合にはまずいものになり得ます。だからアクセスの順序と場所の組み合わせによるのです。アーキテクチャやハードウェアにおける仕事が必要になるかもしれませんが、リファレンスやアドレッシングの機能の一部をハードウェア自体に任せるようにすれば、実現できると思います。データがメモリに来る時点で非常に多くの変換を行えるようなマシンがあります。マッピングをそこで行えるのです。
・私たちに必要なのはもっと高級な言語やドメイン固有言語、そして開発のための本当に良い方法です。
第14章 Bernie Cosell
・私が信じていたことが2つあって、それはとても有効に働いたのですが、プログラムは意味がなければならないということと、本質的に難しい問題というのはごくわずかだということです。すごく難しそうに見えるのは、おそらくはしなければならないことをすっかり理解してはおらず、コードが正しそうに見えるまでハンマーでたたくプログラマによる結果なのです。
・大学によっては9月から5月まで続く2期の授業があって、最初に非常に難しいプログラミングの問題に取り組ませていました。それからいくつもの難問を片付けた後、4月にふたたびそのプログラムに取り組ませるのですが、そのことは最初の時点では言わずにおくのです。そこで意図していたのは、ほんの6ケ月前に完璧に理解したと思っていたことを思い出すのがいかに難しいものか驚かせるということです。
・世の中には、たぶん私を含め、良いプログラマがいて、良いCのプログラムを書くことができます。しかしそれは本来あるべきよりも難しいのです。現代的な環境ではより難しく、それは環境自体が難しくなっているからです。Cの弱さが悪用されたり見落とされたりする可能性のある、注意しなければならない部分が量的に増えています。
・
Javaは正しくない感じがします。私の古い反射神経がそう言っています。Javaは権威主義的すぎます。これはPerlが良いと感じられる理由の1つです。安全でチェックされていますが、とても多角的であり、私の中の芸術家的な部分を解放して、物事を明確に表現し正しいやり方を考えられるようにしてくれます。ある自由を手にできるのです。
私が最初にJavaをいじったとき、まだ小さな言語だったときのことですが、「ああ、これはまた例によって、あんまりできのよくないプログラマを助けようと、できることを制限してまっすぐな細い道を歩かせる言語だな」と思いました。しかし私たちはそういうのが正しい地点に来ているのかもしれません。1パーセントか2パーセントのプログラマだけがすごい作品を作り出せる優れた柔軟な言語を使うには、世界はあまりに危険な場所になってしまったのかもしれません。
第15章 Donald Knuth
・(自分の本で取り上げるアルゴリズムについて)nが2の100万乗より大きいときにlog log nの割合だけ速くなるデータ構造なんかは取り入れません。そういうことをやっている論文がすごくたくさんあります。コンピュータが神のようであるとしたら、原理的にはより速いアルゴリズムが得られるという、一種のゲームをしているのです。
・
問題は、ライブラリを自分で書けないなら、やることはライブラリを呼び出すことだけになり、プログラミングは楽しいものではなくなるということです。プログラミングの仕事がパラメタの正しい組み合わせを見つけるだけということになれば、すごくつまらない話で、そんなことを職業にしたい人がいるでしょうか?
再利用可能ソフトウェアが過度に強調されていて、それは箱を開けて中に何があるか覗くことが決してない世界です。そんなブラックボックスがあるのは結構ですが、ほとんどの場合箱の中身を見ればそれを改善することができるし、箱の中身を一度知ればよりうまく使えるようになるのです。しかしそうする代わりに人々はあらゆるものの周りに閉じた覆いをつけ、世界のプログラマに閉じたものを渡し、プログラマはそれをいじることが許されないのです。彼らにできるのは組み立てることだけです。それでこのサブルーチンを呼ぶときはx0, y0, x1, y1を渡し、こっちのサブルーチンを呼ぶときはx0, x1, y0, y1を渡すというようなことを暗記します。それを正しくやるのが仕事というわけです。
・私にとってプログラミング言語におけるもっとも大きな革命は、C言語におけるポインタの使用です。ある程度複雑なデータ構造があるとき、構造のある部分と別な部分をつなぐ必要があり、それは様々な方法で高級言語に取り入れられています。たとえばアントニー・ホーアはすごくきれいなシステムを持っていました。しかしC言語で追加されたものは、最初私はそれが大きな間違いだと思っていましたが、後になってすごく気に入りました。つまりxがポインタのとき、x+1はxの1バイト後ということではなく、xが何へのポインタかに応じてxの1つ先のノードを指すということです。xが大きなノードを指している場合には、x+1は大きくジャンプすることになります。xが小さなのを指していればx+1は少しだけ移動することになります。私にはこれが記法におけるもっとも目覚ましい進歩に思えます。
#いかにも「Cは遅すぎる、アセンブリ言語で書け」と言ってのけた人らしい意見。
・
ポインタは今では私のお気に入りではなくなりました。私がここに持っているような64ビットコンピュータでは、マシンの能力を本当に生かそうと思うなら、ポインタを使わないほうがよいのです。というのも、このマシンは64ビットレジスタを持っているのにRAMは2GBしかありません。だからポインタは上位32ビットを決して使うことがありません。それでもポインタを使うたびに64ビットを消費し、データ構造のサイズが倍になってしまいます。さらに悪いのは、それがキャッシュを使うということで、キャッシュの半分が無駄になってしまいます。キャッシュはとても高価だというのに。
だからプログラムを本当に限界まで持っていこうと思うなら、ポインタの代わりに配列を使う必要があります。複雑なマクロを書いて、それがポインタを使っているように見えるようにしているのです。これはある意味小さなことで、やがて廃れていくことでしょう。しかし私にとっては、ポインタは低レベルの記法における重要なアイデアだったのです。私がコードを書いたりデバッグしたりするときには、今でもトンプソンとリッチーに感謝の念を抱きます。どちらが考え出したのか知りませんが。
#「だからポインタは上位32ビットを決して使うことがありません」って、ファイルのmmapは?
・アルゴリズムやデータ構造のコミュニティにおけるトレンドで気に入らないのは、彼らが「バロック調」とでも言うしかないデータ構造を追求していることです。それは精緻で巧妙で、知的挑戦という点では賞賛するほかないのですが、不毛なものです。生活につながっていません。別世界に生きているのです。それは結構な世界で、それ自体の組織を持ち、友好的でいい人たちですが、個人的にはあまり魅力を感じないし、実用とは結びついていません。
・誰かほかの人の考え方の中に浸って、そのボキャブラリや記法を解読できる能力はとても重要です。その人たちの考え方や発見した方法を理解できれば、自分で発見をするときに役立ちます。私は過去に優れた人々が言ったことが書かれた文献をよく読みます。今日の観衆からすると変わった方法で表現されているかもしれませんが、彼らの記法を通して彼らの考えを捉えようとするのは価値あることです。
2012年01月18日
Coders at Work まとめ Part 2
『Coders at Work』まとめ Part 1の続き。
第5章 Joshua Bloch
・(プログラマすべてが読むべき本は?)これについては若干複雑な思いがありますが、それでも『デザインパターン』はすべてのプログラマが読むべきだと思います。この本は共通のボキャブラリを与えてくれます。良いアイディアがたくさん詰まっています。一方でスタイルや言語の寄せ集めのようで、古さが感じられるようになりました。それでも間違いなく読む価値はあると思います。
・近ごろではみんな並行性について学ばなければならなくなっています。『Java並行処理プログラミング』はおすすめできます。タイトルにJavaとありますが、内容の多くはどんなプログラミング言語にも使えるものです。
#私からも推薦します。
・(プログラマはなぜ言語について宗教的になるのか?)分かりません。しかし言語を選ぶときには、単に技術的なトレードオフの選択をするだけでなく、コミュニティをも選んでいるのです。これは酒場を選ぶのに似ています。酒場に行くのは良い飲み物を提供してもらうためですが、それは一番重要な部分ではありません。そこにはどんな人がいて、どんな話をしているかということが重要なのです。
・(文芸的プログラミングについて)私が代わりにするのは、コードが読みやすくなるよう、変数名、メソッド名といった識別子の名前を選ぶのに喜んで文字通り何時間も費やすということです。そういった識別子を使った式を読んで、それが英語の文章のように読めるなら、プログラムが正しいものになる可能性は高くなり、ずっと保守しやすくなります。「単なる変数名だろ。時間をかける価値なんてないよ」と言う人は単に理解していないのです。そういう態度では保守可能なプログラムはできません。
#「人の理解」に最適化した名前をつけようとする意図にはうなずけるが、その「人」を実際に使うことなく当てずっぽうだけで最適化しようとするのは、プログラムの実行速度を測定なしで当てずっぽうだけで最適化しようとするのに等しい。APIなどのパブリックな名前については『.NETのクラスライブラリ設計』や後のSimon Peyton Jonesを参照。プライベートな名前の命名に迷うのは、自分がなにをしているかわかっていないことの兆候。
・今日においてさえ、並行処理ユーティリティのためのユニットテストを書くというのはアートに近いのです。
#同期オブジェクト、ダメ! 絶対!
第6章 Joe Armstrong
・
今から思うとおかしいのは、現代的な小道具というのはどれも、実際にはより生産的にしてくれるものではないことです。階層的ファイルシステムでどうやって生産的になるのでしょう? ソフトウェア開発の大部分はどのみち頭の中で行われるのです。あのようなシンプルなシステムのほうが、統制のとれた考え方を引き出します。ディレクトリシステムがなく、すべてのファイルを1つのディレクトリに入れなければならないとしたら、非常に統制が取れている必要があるでしょう。構成管理がないとしたら、非常に統制が取れている必要があるでしょう。そのような統制の取れたやり方をするのであれば、階層的ファイルシステムや構成管理システムがそんなにいいものとも思いません。そういったものは自分の問題を解くという根本的な問題を解決してくれるわけではありません。グループの人々が一緒に働くのを容易にはしてくれるでしょうが、個人にとってはそう違いがあるとは思いません。
それから今日では選択の重荷が大きすぎると思います。かつて私にはFortranしかありませんでした。シェルスクリプトさえなかったと思います。実行するためのバッチファイルとFortranコンパイラだけです。それから本当に必要な場合にはアセンブリ。だから選択の苦しみというのはありませんでした。今時の若いプログラマは大変に違いないと思います。20もの異なるプログラミング言語に、何十というフレームワークとオペレーティングシステムがあります。選択のために身動きできなくなってしまうでしょう。昔は選択による麻痺状態なんていうものはありませんでした。単に始めるだけのことで、言語やなんかに何を使うかという選択は、すでになされていたのです。どれにするかと考えることはなく、ただやり始めれば良かったのです。
・(ソフトウェア再利用について)私はある人たちが「これは本当に不自然なことで、OTPフレームワークに合わせるためコードをねじ曲げることになる」と言うのを耳にしました。だから私は「じゃあOTPフレームワークを書き換えたらいい」と言いました。彼らはフレームワークが変えられるものだと思っていないのです。しかしフレームワークだって一種のプログラムにすぎません。変えるのはむしろ簡単です。だから私が手を入れて、彼らが望むことをできるようにしました。彼らはそれを見て「ああ、本当に簡単ですね」と言い、簡単であることは認めてくれましたが、「でもフレームワークをいじったりするのはプロジェクトマネージャが嫌うんですよ」と言うのです。だったら何か別な名前をつければいいんですよ。
#今の時代の最悪の税金は、セキュリティアップデート。セキュリティアップデートに備える必要がある場合は、よほどのことでないとフレームワークをいじれない。
・長い間私は包括的な誤りを犯していました。その包括的な誤りとは、ブラックボックスを開けないということです。ブラックボックスは手を出せない難しすぎるものであり、開けずにおこうというメンタリティです。
・初心者プログラマがそういった抽象化をすべて開いて見るべきだとは言いません。しかし言っておきたいのは、少なくともそれを開ける可能性について考えてみるべきだということです。その考えをすっかり排除してしまわないことです。直接的な方法が、パッケージ化された方法より早いか見てみるのは価値のあることです。一般にソフトウェアを買ったりほかの人のソフトウェアを使う場合、合わせるためにすごく長い時間がかかることを覚悟しておく必要があります。それは正確にこちらのやりたいことをやってはくれず、少しばかり違ったことをします。その違いを解消するのには長い時間がかかるかもしれないのです。
・再利用性の欠如はオブジェクト指向言語から来るもので、関数型言語では話が違います。オブジェクト指向言語の問題は、それが周りに引きずっている暗黙の環境にあります。バナナが欲しかったのに、手に入れてみたら、バナナを握ったゴリラと、それにジャングルまでついてきたというようなものです。
・(コードを書いてみたら「これはおかしい」と感じて書き直すことについて)こう思ったのを覚えています。「こういったことを全部書かなくとも考えられたらいいのにな」。コードを書かずに洞察を得られたらいいですよね。私は今ではそれができるようになったと思います。20年かかりましたが、私はそれをプログラムの書き方を学んでいた期間だと位置づけています。今ではプログラムの書き方が分かるようになりました。以前はプログラムの書き方を学ぶために実験をしていましたが、今ではプログラムの書き方が分かり、もう実験は必要なくなりました。
・私はどちらかというとCを手で書くよりはプログラムで自動生成しますね。そのほうが簡単ですから。
・「ジョーのデバッグの法則」というのがあります。それは、すべてのバグは最後にプログラムを修正した箇所からプラスマイナス3ステートメント以内にある、というものです。
・Prologはほかのどのプログラミング言語とも違っています。まったく驚くべき考え方を持っています。あらゆる問題に適するものではありません。しかし非常に広い範囲の問題に適しています。広くは使われていません。Prologではプログラムをとても短く書けることを考えると、すごく残念なことです。初めてPrologでプログラムを書いた時にはショックを覚えました。衝撃的な体験だったのです。プログラムがいったいどこにあるのか探し回るような感じです。だってプログラムを書いてはいないのですから。ただシステムや問題に関する事実をいくつか記述しただけです。するとPrologが何をすべきか見つけ出すのです。まったく素晴らしいです。私はErlangなんか捨ててPrologに戻るべきなのかもしれません。
・私が見てきたプログラマについて言えるのは、あらゆる言語に優れているか、どの言語もだめかのどちらかだということです。C言語の優れたプログラマはErlangでも優れたプログラマになります。これは非常に確かな予測を与えてくれます。例外がなくもありませんが、1つの言語で優れた者になるために必要な知的能力は、ほかの言語にも適用可能なのです。
・(ハードウェアの並列性について)データ並列化は、本当に並列なわけではなく、キャッシュの振る舞いにかかわることです。Cのプログラムを効率的にしたいとき、*pがある16ビット境界内にあるとき、*pへのアクセスの後*(p+1)へのアクセスは基本的にタダになります。キャッシュに載っているからです。そうするとどれくらいキャッシュラインを広くするかが悩みどころになります。1回のキャッシュ転送で何バイトのデータを持ってくるべきか? これがデータ並列性で、プログラマは利用できますが、データ構造に細心の注意を払い、それがメモリ上で正確にどのように展開されるか把握する必要があります。非常に煩雑で、あまりやりたいとは思わないでしょう。
#あとでFran Allenがこれと関連する話題に触れる。
第7章 Simon Peyton Jones
・(Microsoftが行うプログラマを対象としたユーザビリティテストについて)
彼らはAPIのテストについても興味深い仕事をしています。レドモンドにいるスティーブン・クラークのグループは、プログラマが新しいAPIを提示されたときにどうするかを、何をしようとしているか口に出してもらうことを通して系統的に観察しています。そしてAPIをデザインした人たちに、マジックミラーの裏から見てもらうわけです。
するとマジックミラー裏の人たちが「だめだめ、そんなことしないで! やり方が違うってば!」と声を上げるわけですが、防音になっています。これはとても示唆に富む体験になります。そしてAPIを修正することになります。率直に言って、プログラミング言語の研究はこういう点が弱いものです。ある部分では、そういった疑問が答えるのが難しいからです。そして文化的にもあまりそういったことに慣れていません。これは弱い部分だと思います。しかしこれは私が個人的に良く議論できる領域でもありません。
・両端キューへのシーケンシャルな実装は、大学1年でやるプログラミングの問題です。それがノードごとにロックをつけた並行版の実装となると、研究論文レベルの問題になります。とても大きなステップです。何かがそんなに難しいのは馬鹿げているくらいです。トランザクショナルメモリを使えば、再び学部の問題のレベルになります。挿入と削除の操作を"atomic"でラップするだけで良いのです。これは驚くべきことだと思います。これは質的な違いです。STMを実装する人たちは、メモリに対するたくさんの変更が間違いなくアトミックに1つの操作としてコミットされるようにする必要があります。比較とスワップだけでこれをやるのは簡単なことではありません。可能ですが、注意深くやる必要があります。
・(プログラマが無人島に持っていくべき本は?)クリス・オカサキの本、"Purely Functional Data Structures"も素晴らしいです。アーサー・ノーマンの授業が1冊の本に拡張されたかのようです。副作用なしで、しかも効率よくキューやルックアップテーブルやヒープを実装する方法について書かれています。すごく良い本ですよ。みんな読むべきです。それに短くて読みやすい本でもあります。
・プログラマとしての生活で最もがっかりさせられるのは、もはや修正ができないようなコードに直面することで、ほかの人が書いたものでもきついことですが、さらに悪いのは自分の書いたものがそうなったときです。これは本当にがっかりすることです。
第8章 Peter Norvig
・(学会の先進的なアイディアを産業界が取り入れるスピードについて)業界がもっと前向きであるべき領域があるのは確かです。「今日すぐに移行することはできないが、10年先にどこへ向かうかの計画を持つべきじゃないか? 今と同じ場所でないとしたら、どうやってそこへ行くのか?」と考える必要があります。
しかし改善する領域は大きなインパクトのあるところにしたいでしょう。多くの場合、プログラミング言語が見ているところはおそらくレベルが低すぎ、言語設計者たちが思っているような大きなインパクトはありません。「俺の新しい輝く言語を見てくれ。この6行のコードが2行で書けるんだ」。それは結構だし、それでより生産的にも、デバッグや保守が楽にもなるでしょう。しかしそのコードは稼働しているシステム全体のごく小さな部分にすぎず、本当に大きな問題は、データを毎日更新し、Webをスクレーピングしてその新しいデータを取り込み、適切なフォーマットにすることかもしれません。だから自分の解いている問題は全体の問題に対してごく小さな部分だということを自覚する必要があり、切り替えを起こさせるには大きな障害があるということです。
・(私たちは今でもアセンブリ言語を学ぶべきなのでしょうか?)
分かりません。クヌースは何でもアセンブリでやれと言っていました。Cで書くのは非効率すぎるということで。これには賛成できません。どの命令が非効率か分かるくらいには知っていたいと思うかもしれませんが、問題はもはや個々の命令のレベルではなくなっています。ここが2命令でなく3命令になっているとかいう話ではありません。ページフォルトやキャッシュミスがあるかという話です。アセンブリ言語を知っている必要はないと思います。アーキテクチャは必要です。アセンブリ言語はどういうものかとか、メモリ階層というのがあって階層を1レベル下ると大きなパフォーマンスペナルティがあるといったことは理解しているべきです。しかしこれは抽象的なレベルで理解できることです。
第9章 Guy Steele
・
私が確信しているのは、1つの言語があらゆる問題を解く上でほかのどの言語よりも優れている、ないしは同等に優れていると考えるのは間違いだということです。アプリケーションの領域ごとに、どの言語が適しているかは違っているものです。
(中略)
問題は、ある小さな一組のアイデアに対して優れた記法を考え出し、それを完全なプログラミング言語にしたいと思った場合、完成させるためにその周りにいろいろなものを構築しなければならず、あらゆることについて良い仕事をしないなら、その1つのアイデアに関しては優れているがほかの部分についてはできの悪い偏った言語を作ることになるということです。
・
Perlは批判できるほど本格的に使ったと言えるか分かりませんが、この言語には引かれませんでした。C++も引かれませんでした。C++のほうは結構書いていますが。今はC++で書こうと思うようなことは、Javaでもっと簡単にできます。効率が最大の関心事というのでなければ。
しかし私はビョーン・ストラウストラップの努力に対する批判者とは見られたくありません。彼は自分で明確な目標を設定していました。それはCと完全に後方互換なオブジェクト指向言語を作るということです。これはとても難しい仕事です。そしてこのような制約の下で、彼は感心するような設計を行い、ずっとよく持ちこたえています。しかしプログラミングにおける目標としてCと後方互換にするという決断には致命的な欠陥があると思います。乗り越えられない困難を生むことになります。Cの型システムは根本的に壊れていますから。ある種の問題を回避するには十分かもしれませんが、完全なものではなく、当てにはできないのです。
・(自身の設計した言語が純粋関数型でないことについて)一方でHaskellはモナドを発見し、I/Oモナドを引き入れ、今度はトランザクショナルメモリモナドを引き込んでいます。関数型言語というのは理論上のことで、助けになることもあるでしょう。一方でどんどん命令的になっています。鏡の国のアリスに出てきた白の騎士を思い出さざるを得ません。「頬髯を緑に染めて、いつも大きな扇を持って誰にも見られぬようにする計画について考えておった」。ある意味で、モナドはこの扇のように見えます。I/Oを引っ張り込んでまた隠してしまうというのは。副作用は本当はあるのか、それとも本当にないのか?
第10章 Dan Ingalls
・
私は多様性を支持する方です。今見た例からも、「いや、みんなに好きなようにやらせよう」と言いたいです。無知によって生じる無駄というのもあるでしょうが、自然選択によって整理されます。そして時折このような未来へと連れて行ってくれる新種が現れるのです。
標準化しようと、1つの方向に向かおうと試みることによって、クリエイティビティが疎外されているような領域はたくさんあると思います。私はJavaに支えられている会社で働いているのであまり言えないんですが、Javaの出現というのはその1つの例だと思います。OOPSLAを見ればよく分かります。Javaが現れたことによって、ほかのオブジェクト指向言語のみならず、動的言語全般に至るまで、活動がスローダウンするか、すっかり止まってしまいました。これは損失だったと思います。
・4半世紀前、私たちは人工知能について考えていました。マシンは当時とは比べものにならないくらい速くなったというのに、私たちはその方面でほとんど何もしていません。いまだにFortranに近いところでやっています。Prologができてずいぶんになります。論理プログラミングでなし得ることはたくさんあります。アセンブリ言語を学んで仕組みを知るべきだと思っているなら、もっと枠を踏み出た、未来の可能性の一部であるようなものに浸るべきだと思います。
2012年01月17日
Coders at Work まとめ Part 1
『Coders at Work』はいい本なので、思いのままにまとめてみた。
ネットに山ほどある「まとめ」の流儀に従い、まとめ元の内容など事実上無視している。ネットの「まとめ」を真に受ける人がいるとは想像したくないが、世の中には底抜けに天井知らずに愚かな人がいるらしいので、一応警告した。
第1章 Jamie Zawinski
・(Emacs LispコンパイラについてStallmanへのメールで)「前のコードはクズだからすっかり書き直した」
・C++には嫌悪しか感じません。あらゆることがあらゆる仕方で間違っています。
#だがそれがいい。プログラミング言語が生み出した究極のパズル、C++。
・Perlは嫌いですね。ひどい言語です。しかしおよそどこにでもインストールされています。
・Objective Cで書きましたが、あれは非常に良い言語です。
#私見では名前システムやGC観が80年代風で嫌い。X Windowみたいなクソ長い関数名がばんばん出てくる。GCが参照カウントで、しかもカウンタが明示的と暗黙的のどっちつかずで、どちらか一方よりも悪い。
・
そうしてNetscapeはCollabraという会社を買収し、私とテリーの上に来る管理組織をまるまる雇い入れたのです。Collabraは私たちがやったのと多くの点で似た製品を出していましたが、違っていたのはWindows版しか作っていなかったことで、マーケットではまったく失敗していました。
それからスタートアップの宝くじに当たってNetscapeに買収されたのです。Netscapeは基本的に会社の指揮を彼らにゆだねました。だから彼らはメールリーダーを引き継いだだけでなく、クライアント部門全体も手に入れたのです。テリーと私はCollabra買収のときNetscape 2.1に取り組んでいましたが、それから書き直しが始まりました。彼らのNetscape 3.0が大幅に遅れそうだったので、私たちのやっていた2.1が3.0になりました。何か出さなきゃいけない時期になっていて、しかもメジャーバージョンアップする必要があったからです。
それで彼らがやっていた3.0が4.0になったのですが、ご存じの通り、それはソフトウェア史上最大の災厄になりました。基本的にはこれがNetscapeを葬ることになりました。息絶えるまでに時間がかかりましたが、実際のところ我々が買収した会社が指揮した書き直しのためでした。彼らはほとんど何も成し遂げず、我々のやってきた仕事や我々の成功をすべて無視し、セカンドシステム症候群に向かってまっしぐらに突き進み、会社を沈没させたのです。
#Collabraという名前は初めて聞いた。構成員の個人名はどう検索しても出てこない(CEOさえ不明)。マーク・アンドリーセンに次ぐB級戦犯としてぜひ知りたいところ。
・いつも何か悪いことをしているような気がするのですが、誰かほかの人の書いたコードを引き継いだとき、それを再利用するよりも自分で書き直したほうが早いことがあります。人のコードを理解し、使い方を学び、デバッグできるくらいによく理解するためにはある程度時間がかかるからです。自分で一から始めたほうが時間が短くて済みます。それはやろうとしたことの80パーセントしかないことになるかもしれませんが、その80パーセントが実際必要なものなのかもしれません。
・できるだけ早く何か画面に出るようにするというのは、私にとって問題に集中する助けになります。次に何をするか決める助けになります。ただ大きなTODOリストを眺めていても、どれからやればいいんだろうとか、そもそもどれからやるかに意味があるのか、と思ってしまいます。しかし実際に目に見えるものがあると、たとえそれが受信箱パーサのデバッグ出力だったとしても、ああ、ここだ! と思います。次に進むべき方向を示してくれます。単に木構造を表示するんじゃなく、HTMLを出したほうがいいかも、とか、そういったことです。あるいはヘッダをもう少し詳細に解析しようとか。そこから次に何を作ればいいか見つけるわけです。
・最近の人はデバッガという概念について混乱しているようです。「なんでそんなもの必要なの? 何をしてくれるの? print文を自動的に入れてくれるの? 分からない。その変な言葉は何に使うの?」最近ではもっぱらprint文が使われているようです。
#私がいわゆる「スクリプト言語」を避けるのは、まともなデバッガがないから。
・長い変数名を使うこと。ハンガリアン記法は好きではありません。普通の英語を使ってそれが何なのか記述することです。ループ変数の場合は自明なので別ですが、一般にできるだけ冗長にしたほうがいいと思います。
#いかにもObjective-Cを気に入る人らしい意見。
・同時期に書かれた本でみんなが最高だと言っていた本に『デザインパターン』があります。私はくだらないと思いましたけど。あれはいわばカットアンドペーストによるプログラミングです。自分のタスクについてじっくり考えるのではなく、レシピ集を眺めて、何かそれっぽいものを見つけ、単に猿真似するんです。そんなのプログラミングじゃありません。塗り絵ですよ。しかし多くの人はそういうのが気に入ったようです。ミーティングで連中はその本で読んだ用語を持ち出して騒いでいました。インバース・リバース・ダブルバックフリップ・パターンとか何とか。ああ、ループのこと? なんだ。
#「デザインパターンはプログラミング言語の欠陥を示している」説に+1。
第2章 Brad Fitzpatrick
・最初にきれいなソースをtarballで手に入れるか、svnからチェックアウトして、ビルドを試みます。まずこのハードルを越える必要があります。多くの人にとってこれがまず大きな障害になるでしょう。ビルドシステムの依存関係や、インストールされていることが前提とされているライブラリなんかがあります。大きなプロジェクトなんかは、ビルド環境が入ったバーチャルマシンを提供してくれればいいのにと思います。
#まさしく。
・僕のコンピュータの体験は、今よりも10年前のほうが幸せだった気がします。10年前のほうがコンピュータは速かったような感じがします。10年前のほうが自分のコンピュータは良い仕事をしてくれた気がします。いろんなものが速くなっていますが、その間にソフトウェアは遅く、バグっぽくなりました。
#デスクトップでは感じない。モバイルは本当にひどい。movaのpreminiを返せ! Windows CEを返せ!
第3章 Douglas Crockford
・私はトンプソンとリッチーがCの整形形式を定義しなかったのがあだになったと思っています。「これは私たちのやり方ですが、皆さんはほかのやり方をしてかまいません」と言うのは、人類全体に大きな損害をもたらしたし、今後もずっと続くことでしょう。
#私見ではPythonの最大の欠陥は、インデントをタブとスペースのどちらかに限定しなかったこと。
・(JavaScriptのユニットテストについて)
JsUniがありますが、UIのコードのテストは非常に難しく、多くのものに依存しているためユニットに分割するのはあまり効果的ではありません。また、私のJavaScriptを書くスタイルのため、クラスでのように整然とユニットに分割することができないのです。クラスベースであればクラスごとにテストを考えることができるわけですが。
JavaScriptでは単独の関数のテストというのはたぶんあまり意味がありません。意味を持つためには状態が必要だからです。JavaScriptでユニットテストをする十分有用な方法というのを、私はまだ見つけられないでいます。
#まさしく。可能ではあるが、カジュアル←→フォーマルの数直線のかなり右側にしか立てない。私にとっては右端はいらないけれど、左端がなければそもそもユニットテストがいらない。ユニットテストのもっとも素晴らしいところは、ほとんど手間なしに左端から右端へとテストを移動させられること。
・(山ほどのブロガーたちが言っていますね。「俺たちがあらゆることをブログに書き、主流メディアはそれで打撃を受けている」)
ええ、素晴らしいことですが、間違っています。私たちは互いにつながり、メッセージを互いに送り合うことができますが、それは機能していません。現状ではノイズばかりです。
第4章 Brendan Eich
・(昔のコンパイラ研究について)当時は優れたボトムアップパーサジェネレータの研究開発が競って行われていました。yaccなんかがやっていることです。形式的純粋さが、極めてきれいなコードへと変換されているのが見て取れました。コンパイラ構築の前段はいつもそうです。当時のコンパイラの後段は伝承とヒューリスティックスの塊でしたけど。
#今は?
・オブジェクト指向やデザインパターンにはまるタイプではありません。エリック・ガンマの本は買っていません。Netscapeには、買収でやってきた、私やジェイミー・ザヴィンスキーの天敵がいて、デザインパターンの本をバイブルみたいに振り回していて鼻につきましたが、彼らは良いプログラマではありませんでした。
・(機械語レベルでの理解について)私は頭のいいJavaScriptプログラマをたくさん知っていますが、最高の人たちはみな「経済」をよく理解しています。彼らはベンチマークを取り、書き進めながらテストをし、引き締まったJavaScriptコードを書きます。それが機械語にどう変換されるのか知っている必要はありません。
・90年代に私が大嫌いだったもの、嫌悪反応を示していたものは、CORBAやCOMやDCOMといったオブジェクト指向のナンセンスすべてです。当時のスタートアップはみんな、起動して"Hello, world"とプリントするだけで20万のメソッド呼び出しを必要とするような狂ったことをやっていました。滑稽です。
・誇大宣伝は良くありません。「デザインパターンが我らを救う」というC++のハイプみたいなのは良くない。もっともあれは80年代の保守的なUnixとCの世界に対する反動だったのかもしれません。
・(プログラミング言語はプログラマが間違いを犯すのをどこまで防止すべくデザインされるべきでしょう?)Javaのような労働者階級の言語はいかれたジェネリックシステムなど持つべきではありません。労働者たちは共変、反変のような型制約の構文がいったい何を意味するのか理解できないでしょう。
#とはいえJavaのジェネリックは大したものではない。暗にC#のことを言っている?
・(プログラミング言語はプログラマが間違いを犯すのをどこまで防止すべくデザインされるべきでしょう?)どこでも同期ブロックを使うべきではありません。ミューテックスやスピンロックは間違いなく使うべきではありません。
・ダグはみんなにいろいろなパターンを教えましたが、私はピーター・ノーヴィグと同意見です。パターンは言語にある欠陥を示しているのです。
・
トランザクショナルメモリに大きな期待が寄せられていますが、それでは解決しないでしょう。膨大な数のプロセッサ上でネストしたトランザクションがロールバックしたり競合したりするようにはならないでしょう。効率的ではありません。場合によっては正しく機能しないこともあるでしょう。あらゆる並行アルゴリズムや並列アルゴリズムをその上に乗せられるとは思えないし、試みるべきでもないでしょう。
ジョー・アームストロングのような人たちは何も共有しないというアプローチでとても良い仕事をしています。ブラウザの実装中の様々なカスタムシステムにもそれを見ることができます。Chromeはその中でも大きなものです。私たちもJavaScriptの実装で私たちなりにそれをやっています。しかし無共有アプローチには、私の知る限り学者は興味さえ持ちません。トランザクショナルメモリは特にコンピュータアーキテクチャ系の人にはもっと興味深いものですが、それはそのための良い命令セットやハードウェアのサポートというのを追求できるからです。しかしそれで私たちが直面する問題のすべてが解決されるわけではありません。
・マルチスレッドは率直に言って怖いものです。私が結婚して子どもを持つようになる以前には、それが私の人生の多くの部分を占めていたからです。並行性や、あらゆる可能な実行順の組み合わせを考慮するというのは、短いシナリオに対してさえ、多くの人が備えのできていないことでした。自分のコードをほかの人のコードと組み合わせるとなると、もう手に負えません。状態空間を頭の中に描くことができなくなります。ほとんどの人はついて行けなくなります。Slashdotの威勢の良い連中みたいになれれば気楽ですが。私は「スレッドは苦痛だ」とブログで書くと、誰かが「あいつ何も知らねぇんだな。本物のプログラマじゃないってことだ」みたいなことを書きます。勘弁してほしいです。私はニュージーランドやオーストラリアまで出向いて成果も収めました。しかしそれは間違いなく苦痛で非常に時間のかかることでした。オスカー・ワイルドがかつて社会主義について言ったように、それは「あまりに多くの夕べを必要とする」のです。
・
私は年を取るにつれ疑い深くなり、うまくもなりましたが、それでも楽観的になっている場合があります。頭の中でピノキオに出てくるコオロギのように囁くのです。「何かを見落としていてバグを作っているぞ」。そういう問題は今でも起きます。
時々自分で分かるときがあります。どこかで間違っているというのが本当に分かります。後頭部のところで何かが知らせるのです。実際には後頭部なのかどうか、その微小器官がどこにあるか分かりませんが、いずれにせよ、何か気をつけなきゃいけないものがあると感じます。
Part 2につづく。紅茶ボタンもよろしくお願いします。
2012年01月11日
時間
MZ-700のキャラグラを作ろうとしたら、ここのWeb上のエディタが使えなかったので、作ってみた。
MZ-700 キャラグラの世界
MZ-700のことを少し調べ、エミュレータも動かしてみた。「DOSBoxの中で動かせ」(エミュレータ in エミュレータ!)と言われたり、GRAPHキーを押した状態から復帰するのが困難だったり、添付のHu-BASICが動かなかったりで、さんざんな目にあった。
きっと昔はみな、なんの問題もなくすんなり動いたのだろう。時間は流れてゆく。
2012年01月01日
正規表現マッチングはMap-Reduceできる
グレゴリオ暦で新年を祝われる皆様、あけましておめでとうございます。
今日のお題は正規表現。ただしチューリング完全なPCREではなく、有限オートマトンにもとづく本来の正規表現である。
一個の巨大な文字列に対する正規表現マッチングをMap-Reduceで分散計算することはできないと思い込んでいるマヌケな子はいねーがー? できそうな気はするけれどアルゴリズムがわからないアホな子はいねーがー? 大丈夫、このエッセイを読むまで私にもわからなかった。アホはあなただけではない。といってもなんの慰めにもならないが。
(このエッセイは正規表現のインクリメンタルマッチングの計算量について論じているが、分散計算のほうが例として自然と思ったのでそうした)
英語とHaskellができてモノイドとfingertreeが常識な人なら元のエッセイを読めばすべて一目瞭然だと思うが、私は英語以外まるでダメなので、理解するまでにすさまじく時間がかかった。日本語でこの問題を説明しているサイトはどうもないようなので、ここに書き留めておく。なお正規表現と有限オートマトンは常識とする。
正規表現『.*(.*007.*).*.』に対応するステートマシン図は以下のとおり:
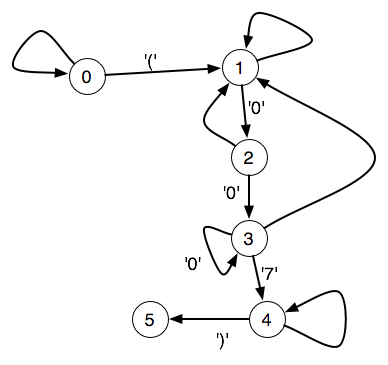
正規表現マッチングをごく手続き的に平凡に考えるなら、初期ステートの0にセットしたステートマシンを文字列の上に走らせ(テープの上を走るチューリングマシンのイメージだ)、完走後のステートを調べて、もし5ならマッチ、ということになるだろう。
このステートマシンは、自分自身のステート(0~5の6択)を文字ごとに逐次的に変更してゆくことで動作する。だから正規表現マッチングをMap-Reduceするにはどうすればいいかわからない、ということになる。
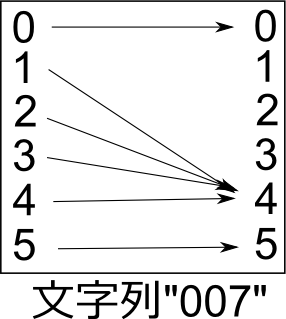
『abc(007007)abc』という文字列を例に、逐次的な変更の様子を見てみると:
state 0 0 0 0 1 2 3 4 4 4 4 5 5 5 5 string a b c ( 0 0 7 0 0 7 ) a b c
ステート0のステートマシンは走行開始直後にまず文字'a'を見て、自分自身のステートを0のままにする。'b'、'c'も同様にして通過し、文字'('を見てついに自分自身のステートを1に変更する。それに続く文字'0'を見てステートを2に――という具合だ。
上の表を見てわかるとおり、同じ文字'0'に対して、ステートマシンはさまざまな反応をしている。最初の文字'0'を見たときには、自分自身のステートを2に変更している。2度目の文字'0'を見たときには自分自身のステートを3に変更し、それ以降に見たときにはもう自分自身のステートを変更することはない。
もちろんステートマシンは文字'0'の出現回数を数えているわけではない。ステートマシンの動作(=自分自身のステートをどう変更するか)は、自分自身のステートと文字だけによって決定されている。文字'0'を見たときのステートマシンの動作を図にすると:
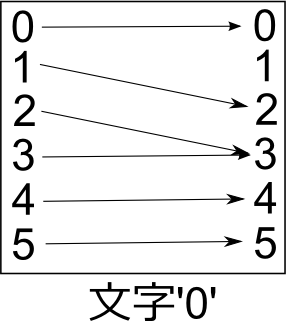
この図は文字'7'についても描ける:
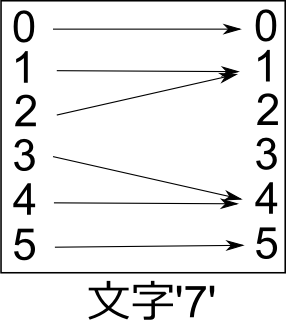
左右に続けて描くと、ステートマシンの逐次的な動作を目で追うことができる:
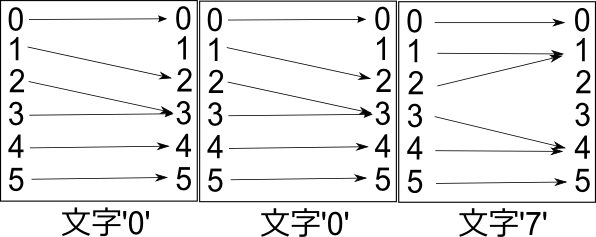
さてここまでは個々の文字についてステートマシンの動作を図に描いてきた。が、上の続けて描いた図を見ると、まったく同じ形式で、文字列についての図が描けることに気付く:
3つの動作を結合して1つの動作にしたわけだ。
この結合は、文字列『007』の例でもわかるとおり、隣り合う動作同士であれば行える。文字列の先頭から逐次的に結合してゆく必要はない。たとえば文字列『abc(』と『)abc』の動作をそれぞれ計算し、それをさらに文字列『007』の動作と続けて描くと:
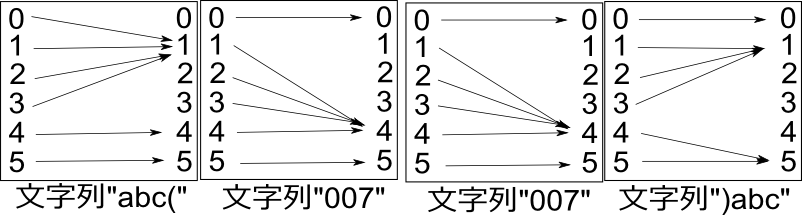
これは文字列『abc(007007)abc』の動作となる。
文字を動作に変換するのがMap、隣り合う動作同士を結合するのがReduceであることは言うまでもない。